

こんにちはーーー
Pythonを使って、株式投資に関するツイートを検索して、csv出力するプログラムを作りました。
“いいね”が多い方が有益な情報が多いかと思い、いいねの数にリミットをかけて検索できるようにしています。
この記事が誰かの役に立てば幸いです。
また、動画もありますので必要に応じてご確認いただければと思います。
プログラム全文
まず最初にプログラム全文を載せておきます。
import tweepy
import csv
def get_api():
keys = dict(
screen_name = '*******', #自分のアカウント名
consumer_key = '********', #Twitter APIから取得
consumer_secret = '***********', #Twitter APIから取得
access_token = '***********', #Twitter APIから取得
access_token_secret = '***********', #Twitter APIから取得
)
SCREEN_NAME = keys['screen_name']
CONSUMER_KEY = keys['consumer_key']
CONSUMER_SECRET = keys['consumer_secret']
ACCESS_TOKEN = keys['access_token']
ACCESS_TOKEN_SECRET = keys['access_token_secret']
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
return api, SCREEN_NAME
def search(api):
tweet_data = [] #取得したツイートを格納するリスト
for tweet in api.search(q="株式投資 min_faves:10 min_retweets:0 exclude:retweets",tweet_mode='extended',count=100):
try:
tweet_data.append(
[tweet.id, tweet.user.screen_name,tweet.created_at,tweet.full_text.replace('\n',''),
tweet.favorite_count, tweet.retweet_count, tweet.user.followers_count, tweet.user.friends_count])
except Exception as e:
print(e)
with open('./search_test.csv', mode='w',newline='',encoding='utf-8-sig') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["id","user","created_at","text","fav","RT","follower","follows"])
writer.writerows(tweet_data)
pass
if __name__ == '__main__':
api, SCREEN_NAME = get_api()
search(api)
実効結果
↓のように、id、user名、ツイート内容、いいね数、RT数、フォロワー数、フォロー数を転記したcsvを出力することができます。
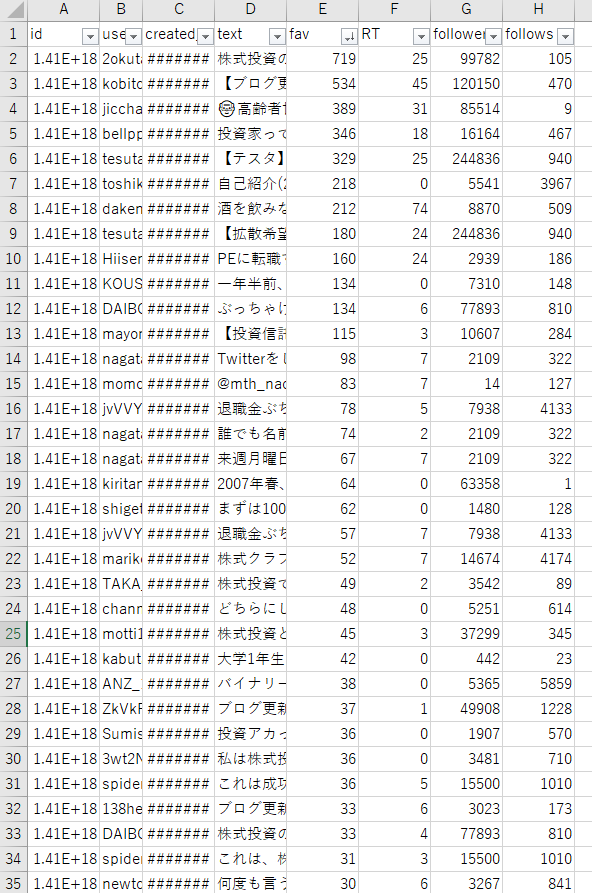
プログラムの詳細
必要なモジュール
本プログラムに必要なのは、tweepyとcsvになります。
import tweepy
import csv
API取得関数
↓の***の所に自分のアカウントキーを入力する必要があります
def get_api():
keys = dict(
screen_name = '*******', #自分のアカウント名
consumer_key = '********', #Twitter APIから取得
consumer_secret = '***********', #Twitter APIから取得
access_token = '***********', #Twitter APIから取得
access_token_secret = '***********', #Twitter APIから取得
)
SCREEN_NAME = keys['screen_name']
CONSUMER_KEY = keys['consumer_key']
CONSUMER_SECRET = keys['consumer_secret']
ACCESS_TOKEN = keys['access_token']
ACCESS_TOKEN_SECRET = keys['access_token_secret']
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
return api, SCREEN_NAME
検索してCSV出力する関数
for文の箇所でツイートを検索しています。
qに検索したワードと、いいねとRTのリミッターを記載します。
countに検索回数を記載します。
with openでcsvを作成して、上記で検索した結果をcsvに貼り付けます。
def search(api):
tweet_data = [] #取得したツイートを格納するリスト
for tweet in api.search(q="株式投資 min_faves:10 min_retweets:0 exclude:retweets",tweet_mode='extended',count=100):
try:
tweet_data.append(
[tweet.id, tweet.user.screen_name,tweet.created_at,tweet.full_text.replace('\n',''),
tweet.favorite_count, tweet.retweet_count, tweet.user.followers_count, tweet.user.friends_count])
except Exception as e:
print(e)
with open('./search_test.csv', mode='w',newline='',encoding='utf-8-sig') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["id","user","created_at","text","fav","RT","follower","follows"])
writer.writerows(tweet_data)
pass
関数の実行
最後にそれぞれの関数を実行すればcsvが出力されます。
if __name__ == '__main__':
api, SCREEN_NAME = get_api()
search(api)
以上になります!
ではまた!


コメント