

こんにちはーー
プログラミングを使って株関連の人気のチャンネルを導出したのでプログラムコードと合わせて記事にしました。
この記事が誰かの役に立てば幸いです。
ざっくり動画にもしています。
概要
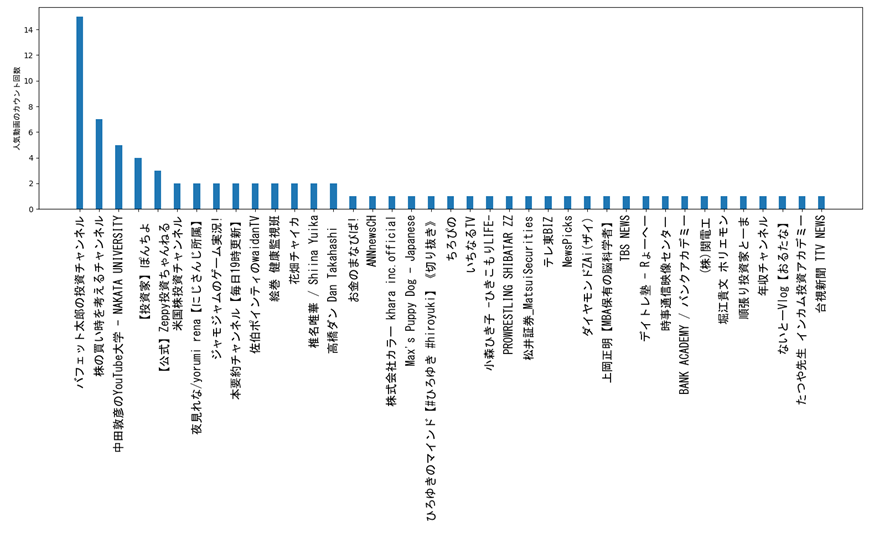
“株”関連で再生数が多い順に100動画を抽出し、チャンネル毎に登場回数をカウントすることで人気チャンネルを算出しました。
プログラミング言語はPythonを使用しています。
結果
株で人気チャンネルベスト10は↓でした。
| 両学長 リベラルアーツ大学 |
| バフェット太郎の投資チャンネル |
| 株の買い時を考えるチャンネル |
| 中田敦彦のYouTube大学 – NAKATA UNIVERSITY |
| 【投資家】ぽんちよ |
| 【公式】Zeppy投資ちゃんねる |
| 米国株投資チャンネル |
| 夜見れな/yorumi rena 【にじさんじ所属】 |
| ジャモジャムのゲーム実況! |
| 本要約チャンネル【毎日19時更新】 |
グラフ化したら1位がなぜか消えてますね・・・これは改良せねば・・・
コード
使用したコードは↓です。
#APIのキーは自分で取得して****の箇所に記載する必要があります。
from apiclient.discovery import build
import pandas as pd
import openpyxl
from openpyxl.styles.fonts import Font
import pandas as pd
import collections
import numpy as np
import matplotlib.pyplot as plt
#***には各自のkeyの記入が必要です
YOUTUBE_API_KEY = '********************************'
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)
def get_video_info(part, q, order, type, num):
dic_list = []
search_response = youtube.search().list(part=part,q=q,order=order,type=type)
output = youtube.search().list(part=part,q=q,order=order,type=type).execute()
#一度に5件しか取得できないため何度も繰り返して実行
for i in range(num):
dic_list = dic_list + output['items']
search_response = youtube.search().list_next(search_response, output)
output = search_response.execute()
df = pd.DataFrame(dic_list)
#videoId取得
df1 = pd.DataFrame(list(df['id']))['videoId']
#取得必要な動画情報だけ取得
df2 = pd.DataFrame(list(df['snippet']))[['channelTitle','publishedAt','channelId','title','description']]
ddf = pd.concat([df1,df2], axis = 1)
return ddf
def export_youtube_csv(search_word):
# 処理を実行
df = get_video_info(part='snippet', q=search_word, order='viewCount', type='video', num = 20)
ldc_data = []
# 再生回数を取得
for i in df.videoId:
statistics = youtube.videos().list(part = 'statistics', id = i).execute()['items'][0]['statistics']
try:
ldc_data.append([statistics['viewCount'], statistics['likeCount'], statistics['dislikeCount'],statistics['commentCount']])
except:
try:
ldc_data.append([statistics['viewCount'], 0, 0, statistics['commentCount']])
except:
try:
ldc_data.append([statistics['viewCount'], statistics['likeCount'], statistics['dislikeCount'],0])
except:
ldc_data.append([statistics['viewCount'], 0, 0, 0])
# 再生数 高評価 低評価 コメント数を追加
df_ldc = pd.DataFrame(ldc_data, columns=['view_count', 'good', 'bad', 'commnent_count'])
# タイトル情報などと再生数などのデータフレームを結合
df_concat = pd.concat([df, df_ldc], axis=1)
df_concat.to_csv(name_csv, encoding='utf_8_sig')
return df_concat
q=input("検索したいワードを入力してください:")
name_csv = "./test.csv"
df2 = export_youtube_csv(q)
df2.head()
########################################################################################################################
print("エクセル変換")
name_xlsx = "./test.xlsx"
path = name_csv
out = name_xlsx
data =pd.read_csv(path)
data.to_excel(out,index=False)
wb = openpyxl.load_workbook(out)
ws = wb['Sheet1']
font = Font(bold=False,name="Meiryo UI")
for row in ws.iter_rows():
for cell in row:
ws[cell.coordinate].font = font
wb.save(out)
#####################################################################################
print("カウント開始")
name_xlsx = out
out_xlsx ="./addd_count.xlsx"
#エクセルの読み込み
wb = openpyxl.load_workbook(name_xlsx)
ws = wb['Sheet1']
#リストの作成
list=[]
max_row = ws.max_row
for i in range(2,max_row):
cha = 'C'+str(i)
cha2 = ws[cha].value
list.append(cha2)
#重複をカウント
print('重複をカウント')
c = collections.Counter(list)
print('降順でソート')
count = 0
for k, v in sorted(c.items(), key=lambda x: -x[1]):
count = count + 1
ws['O'+str(count)] = str(k)
ws['P'+str(count)] = v
#フォントの変換
font = Font(bold=False,name="Meiryo UI")
for row in ws.iter_rows():
for cell in row:
ws[cell.coordinate].font = font
#セーブ
wb.save(out_xlsx)
print('エクセルの出力完了')
############################################################
#グラフ化
print('グラフ化を開始')
name_xlsx = out_xlsx
#エクセルの読み込み
wb = openpyxl.load_workbook(name_xlsx)
ws = wb['Sheet1']
#リストの箱作成
list1=[]
list2=[]
#エクセルからリストへ追加
max_row = ws.max_row
for i in range(2,max_row):
cha1 = 'P'+str(i)
if ws.cell(row=i,column=16).value != None:
cha11 = ws[cha1].value
list1.append(cha11)
for j in range(2,max_row):
cha2 = 'O'+str(j)
if ws.cell(row=j,column=15).value != None:
cha22 = ws[cha2].value
list2.append(cha22)
height = list1
labels = list2
width = 0.35
#グラフのサイズ指定
plt.figure(figsize=(15,10))
#Yラベルの追加
plt.ylabel("人気動画のカウント回数",fontname="MS Gothic")
#リストをグラフ化
plt.bar(labels, list1, width)
#Xラベルの書式設定
plt.xticks(rotation=90, fontsize=15,fontname="MS Gothic")
plt.subplots_adjust(bottom=0.5)
#グラフ表示
plt.show()

コメント