
こんにちはーー
PythonでYoutube動画を文字起こしするコードを書いたので記事にします。
動画編集に役立つかも!?
誰かの役に立てば幸いです。
概要は動画にもしています。
概要
適当に出てきた↓の天気予測のYouTube動画の文字起こしを行います
コードの概要
作成したスクリプトの一覧
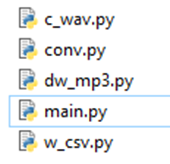
作成したスクリプトの詳細
| ファイル名 | 実行している内容 |
| Main.py | 共通の変数定義、作成した関数の実行 |
| dw_mp3.py | Youtubeから音声ファイル(mp3)をダウンロード |
| Conv.py | ダウンロードしたmp3をwavに変換 |
| c_wav.py | 容量の重いファイルは文字起こしできないためwavを分割 |
| w_csv.py | wavそれぞれに文字起こしを実行 |
コード詳細
main.py
import dw_mp3
import conv
import c_wav
import w_csv
name_mp3='test_voice.mp3'
name_wav="test.wav"
name_csv="test.csv"
url = input('Enter URL:')
dw_mp3.dw_mp3(url,name_mp3)
conv.conv(name_mp3,name_wav)
c_wav.c_wav(name_wav)
w_csv.w_csv(name_csv)
print("全ての処理が完了しました")
dw_mp3.py
import youtube_dl
import os
from pathlib import Path
def dw_mp3(url,name_mp3):
# 初期設定
ydl = youtube_dl.YoutubeDL({'outtmpl': '%(id)s%(ext)s',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '192',
}]
})
# 動画情報をダウンロードする
with ydl:
result = ydl.extract_info(
url,
download=True
)
filename_before1 = url[32:] + 'mp4' + '.mp3' # ファイル名にwebmが付くのでその対応
filename_after1 = name_mp3
current_dir = Path(os.getcwd())
os.rename(current_dir/filename_before1, current_dir/filename_after1)
print('音声ファイルのダウンロードが完了しました')
conv.py
import pydub
def conv(name_mp3,name_wav):
base_file=pydub.AudioSegment.from_mp3(name_mp3)
base_file.export(name_wav,format="wav")
c_wav.py
import wave
import struct
import math
import os
from scipy import fromstring, int16
def c_wav(name_wav):
#A列~ZZ列までの場合
def toAlpha2(num):
i = int((num-1)/26)
j = int(num-(i*26))
Alpha = ''
for z in i,j:
if z != 0:
Alpha += chr(z+64)
return Alpha
#読み込むファイル名
f_name = name_wav
#切り取り時間[sec]
cut_time = 10
# 保存するフォルダの作成
file = os.path.exists("output")
print(file)
if file == False:
os.mkdir("output")
def wav_cut(name_wav,time):
# ファイルを読み出し
wavf = name_wav
wr = wave.open(wavf, 'r')
# waveファイルが持つ性質を取得
ch = wr.getnchannels()
width = wr.getsampwidth()
fr = wr.getframerate()
fn = wr.getnframes()
total_time = 1.0 * fn / fr
integer = math.floor(total_time) # 小数点以下切り捨て
t = int(time) # 秒数[sec]
frames = int(ch * fr * t)
num_cut = int(integer//t)
# 確認用
print("Channel: ", ch)
print("Sample width: ", width)
print("Frame Rate: ", fr)
print("Frame num: ", fn)
print("Params: ", wr.getparams())
print("Total time: ", total_time)
print("Total time(integer)",integer)
print("Time: ", t)
print("Frames: ", frames)
print("Number of cut: ",num_cut)
# waveの実データを取得し、数値化
data = wr.readframes(wr.getnframes())
wr.close()
X = fromstring(data, dtype=int16)
print(X)
for i in range(num_cut):
print(i)
# 出力データを生成
outf = 'output/' + str(toAlpha2(i+1)) + '.wav'
start_cut = i*frames
end_cut = i*frames + frames
print(start_cut)
print(end_cut)
Y = X[start_cut:end_cut]
outd = struct.pack("h" * len(Y), *Y)
# 書き出し
ww = wave.open(outf, 'w')
ww.setnchannels(ch)
ww.setsampwidth(width)
ww.setframerate(fr)
ww.writeframes(outd)
ww.close()
wav_cut(f_name,cut_time)
w_csv.py
import csv
import os
import speech_recognition as sr
import csv
def w_csv(name_csv):
count=0
with open(name_csv,'w') as f:
writer = csv.writer(f)
for fd_path, sb_folder, sb_file in os.walk('./output/'):
for fil in sb_file:
count= count+1
file_name=fd_path +fil
r = sr.Recognizer()
with sr.AudioFile(file_name) as source:
audio = r.record(source)
text = r.recognize_google(audio, language='ja-JP') # 英語の場合はen-US
print(count,fil," 文字起こし完了")
with open(name_csv, 'a', newline='',encoding="shift_jis") as csvfile:
write = csv.writer(csvfile, delimiter=' ')
write.writerow()
実行結果
↓が実行結果です。
まあまあ変換できていますが、所々間違えていますね・・
| 明日の洗濯 天気予報です 明日か パンスト というところも多くなりそうです 明日はお天気の分布から確認していきましょう 北日本は5 |
| 雨が降っていても だんだんと天気は回復していきます 漢方や中部近畿 中国地方は晴れて日差しが届くよ それ以降で日からね |
| 九州や 四国 だんだんと雨が降り出します 手を待って雷を伴うこともありそうです それでは続いて |
| 電気室確認していきましょう それ取り方天気は回復していくんですが 5000円ほど 雨に要注意 仙台周辺は午後に |
| 理由があり また 関東から中国地方に関しては晴れて 暑さ ちゃんとですただ ゆっくりと雲が増えていくため近畿周辺 など |
| 良さそうでさらに 四国や 九州 こちらは雨が降り 明日の洗濯物の外干し は 無理そうです 沖縄では にわか雨の可能 |
| 春雨 お気をつけください また 洗濯 天気予報については 何にもアプリからもご確認いただけます ご覧のように 夜間や 昼間 |
| 今日家の洗濯情報が見られますので是非チェックしてみて下さい 以上洗濯情報でした |
以上です!!


コメント